Spark Data Locality
Thanks Pawel Niezgoda for providing information.
After adding some additional logic to already working spark job, performance went down: union of two small kafka streams took 6s, while all other tasks had very small processing time (<50ms). 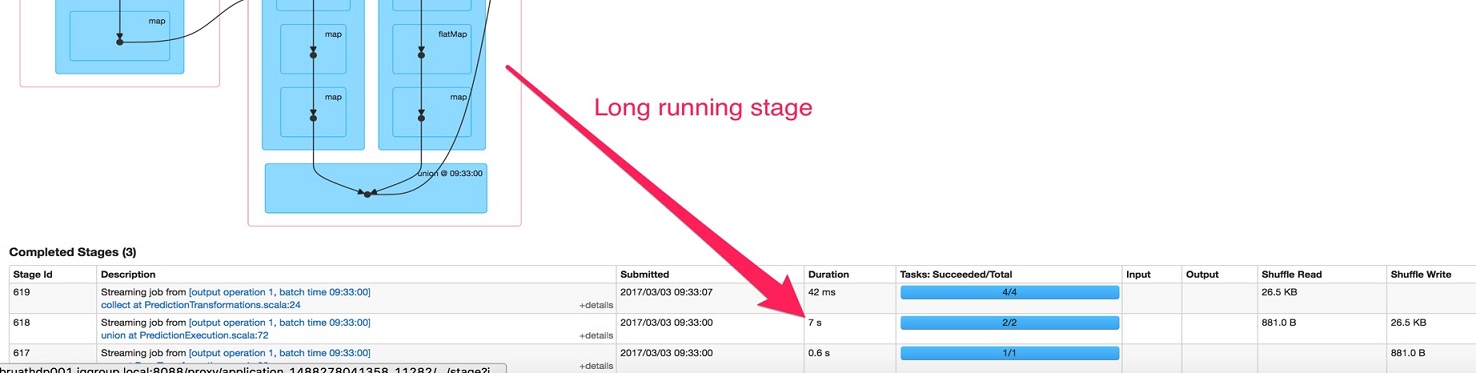
Investigation of this problem showed that the root was spark scheduling. One of the tasks was scheduled with 6 seconds delay for no obvious reason. 
So, launch time of two tasks differ in 6s. Screenshot was done with 2 executors (2 cores each) configuration. Adding more executors and cores didn’t help.
Searching similar problems in google gave result of spark jira ticket. It matched perfectly described situation: the two tasks in the single stage with different locality level. Default value for spark.locality.wait is 3s. So, we were waiting 2 times for 3 seconds to start execution.
Setting param spark.locality.wait to 0 seconds resolve the problem.
What is data locality
Data locality is used to describe how spark maps tasks and input data. It is done to minimize overhead to transfer input data to task. Here you can find detaied post how Spark calculates data locality for RDD.
according to spark documentation there are 5 types of data locality:
- PROCESS_LOCAL
- NODE_LOCAL
- NO_PREF
- RACK_LOCAL
- ANY
After some node finished current work, Spark starts look for new task for it. Going though all pending tasks Spark tries to find task with data locality not greater than the current MaxDataLocality. MaxDataLocality is calculated based on diff between current time and last launch time: curTime - lastLaunchTime >= localityWaits(currentLocalityIndex).
Wait time is configured by spark job configuration:
- spark.locality.wait (change wait time for all cases)
- spark.locality.wait.node (for NODE_LOCAL)
- spark.locality.wait.process (for PROCESS_LOCAL)
- spark.locality.wait.rack (for RACK_LOCAL)
The wait timeout for fallback between each level can be configured individually or all together in one parameter; see the spark.locality parameters on the configuration page for details.
See class org.apache.spark.scheduler.TaskSetManager for mode detailed logic of recalculating locality levels available for execution.