Produce result of Spark Stream job to Kafka
Environment
kafka 0.9 spark 1.6
Producing to kafka according to documentation
Quite often problem: you have spark streaming job and result of it should be pushed to kafka. In most cases when you google for ‘spark streaming prodcue to kafka’, you will find example like:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { iter =>
val producer = new KafkaProducer[K,V](updateClientId(kafkaProducerConfig))
...user producer to send messages...
}
}Problem
This code means, that for every RDD for every microbatch, new kafka producer will be created. This common approach was working for a long time for us. Until we deployed spark job with microbatch size 500ms and 64 partitions. After several days of running, we noticed, that GC on kafka jvm is not performing good (constant major GC).
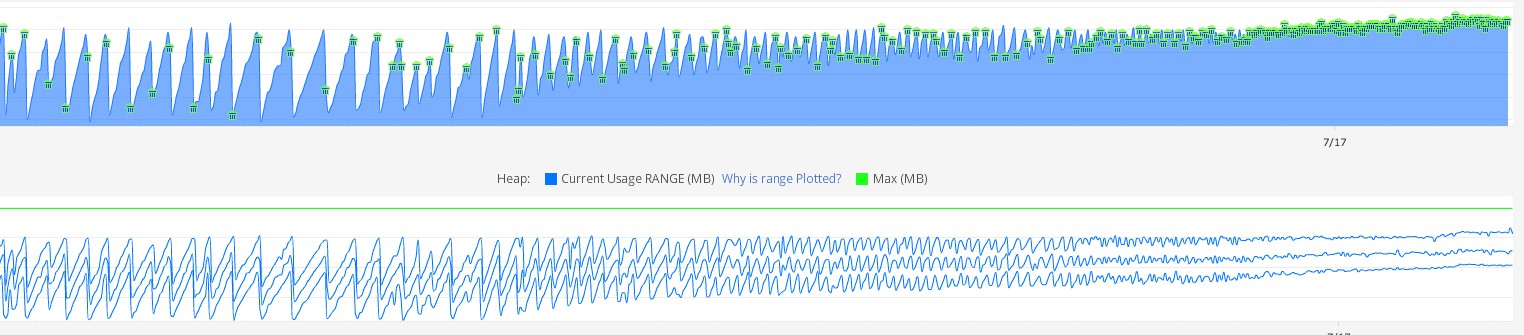
Heap dump of kafka showed that there were huge amount of JMX metrics for kafka producers. I’m not sure that it is a memory leak in Kafka, as it was able to clean up memory before we significantly increased amount of producers created every second. There is one post in stackoverflow that looks similar to our problem.
Solution
Obvious soltuion: decrease of amount new producers created. That mean that we should reuse the same producer. There are 2 posts for (Marcin Kuthan)[http://mkuthan.github.io/]
- broadcast lazy initialized kafka procuder to each executor
- hold map of producers in object (singleton)
Both solutions are working. However, second one requires less code changes.
Broadcast producer
First post in allergo technical blog.
class KafkaSink(createProducer: () => KafkaProducer[String, String]) extends Serializable {
lazy val producer = createProducer()
def send(topic: String, value: String): Unit = producer.send(new ProducerRecord(topic, value))
}
object KafkaSink {
def apply(config: Map[String, Object]): KafkaSink = {
val f = () => {
val producer = new KafkaProducer[String, String](config)
sys.addShutdownHook {
producer.close()
}
producer
}
new KafkaSink(f)
}
}Usage:
val kafkaSink = sparkContext.broadcast(KafkaSink(conf))
dstream.foreachRDD { rdd =>
rdd.foreach { message =>
kafkaSink.value.send(message)
}
}Hold map of producers in object (singleton)
second post. Partial code
object KafkaProducerFactory {
private val producers = mutable.Map[Map[String, String], KafkaProducer[Array[Byte], Array[Byte]]]()
def getOrCreateProducer(config: Map[String, String]): KafkaProducer[Array[Byte], Array[Byte]] = {
producers.getOrElseUpdate(config, {
logger.info(s"Create Kafka producer , config: $finalConfig")
val producer = new KafkaProducer[Array[Byte], Array[Byte]](finalConfig)
sys.addShutdownHook {
logger.info(s"Close Kafka producer, config: $finalConfig")
producer.close()
}
producer
})
}
}Usage:
dstream.foreachRDD { rdd =>
rdd.foreach { message =>
val producer = KafkaProducerFactory.getOrCreateProducer(config)
... send messages using producer...
}
}For more details I suggest to look in github